"think" 도구: Claude가 멈추고 생각할 수 있도록 하기
📄 원문: The "think" tool: Enabling Claude to stop and think
- 출처: The "think" tool: Enabling Claude to stop and think
- 저자: Anthropic
- 원문 발행일: 2025년 3월 20일
- 라이선스: 저작권 Anthropic
- 번역일: 2025년 6월 27일
- 번역 및 감수: Claude and 공부하우
- 참고: 이 번역은 교육 목적으로 작성되었으며, Anthropic의 공식 번역이 아닙니다.
⚖️ 저작권 안내
이 번역문은 교육 및 정보 제공 목적으로 작성되었습니다. 원문의 저작권은 Anthropic에 있으며, 이 번역은 Anthropic의 공식 번역이 아닙니다.
본 번역은 다음과 같은 교육적 공정 사용(Fair Use) 원칙에 따라 제공됩니다:
- 비영리 교육 목적
- 원문 출처의 명확한 표시
- 한국어 사용자의 기술 이해 증진을 위한 변형적 사용
- 원저작물의 시장 가치에 부정적 영향을 미치지 않음
저작권 관련 문제가 제기될 경우, 즉시 적절한 조치를 취하겠습니다. 상업적 사용이나 재배포 전에 원저작권자의 허가를 받으시기 바랍니다.
문의사항이나 우려사항이 있으시면 오른쪽 템플릿 복사를 클릭 하신 뒤, 연락 페이지를 통해 알려 주시기 바랍니다.
Claude의 복잡한 문제 해결 능력을 지속적으로 향상시키면서, 우리는 특히 효과적인 접근법을 발견했습니다: 복잡한 작업 중에 구조화된 사고를 위한 전용 공간을 만드는 "think" 도구 ("think" tool)입니다.
이 간단하면서도 강력한 기술은 - 아래에서 설명하겠지만 Claude의 새로운 "확장된 사고 (extended thinking)" 기능과는 다릅니다 - Claude의 에이전틱 도구 사용 능력에서 놀라운 개선을 가져왔습니다. 여기에는 정책 준수, 일관된 의사 결정, 다단계 문제 처리가 포함되며, 모두 최소한의 구현 오버헤드로 가능합니다.
이 글에서는 검증된 벤치마크 결과를 기반으로 개발자를 위한 실용적인 지침을 공유하며, 다양한 애플리케이션에서 "think" 도구를 구현하는 방법을 살펴보겠습니다.
"think" 도구란 무엇인가?
"think" 도구를 통해 우리는 Claude에게 최종 답변에 도달하는 과정의 일부로 추가적인 사고 단계를 포함할 수 있는 능력을 제공합니다. 이때 전용 공간까지 함께 제공됩니다.
확장된 사고와 비슷하게 들리지만, 이는 다른 개념입니다. 확장된 사고는 Claude가 응답 생성을 시작하기 전에 수행하는 모든 것에 관한 것입니다. 확장된 사고를 통해 Claude는 행동을 취하기 전에 계획을 깊이 고려하고 반복합니다. "think" 도구는 Claude가 응답 생성을 시작한 후, 앞으로 나아가는 데 필요한 모든 정보를 가지고 있는지 멈추고 생각하는 단계를 추가하기 위한 것입니다. 이는 특히 도구 호출의 긴 체인을 수행하거나 사용자와의 긴 다단계 대화에서 유용합니다.
이는 "think" 도구를 Claude가 사용자 쿼리만으로는 응답을 구성하는 데 필요한 모든 정보를 갖지 못한 경우와 외부 정보(예: 도구 호출 결과의 정보)를 처리해야 하는 경우에 더 적합하게 만듭니다. "think" 도구로 Claude가 수행하는 추론은 확장된 사고로 얻을 수 있는 것보다 덜 포괄적이며, 모델이 발견하는 새로운 정보에 더 집중합니다.
우리는 비순차적 도구 호출이나 간단한 지시 따르기와 같은 더 간단한 도구 사용 시나리오에는 확장된 사고를 사용할 것을 권장합니다. 확장된 사고는 코딩, 수학, 물리학과 같이 Claude가 도구를 호출할 필요가 없는 사용 사례에도 유용합니다. "think" 도구는 Claude가 복잡한 도구를 호출해야 하거나, 긴 도구 호출 체인에서 도구 출력을 신중하게 분석해야 하거나, 상세한 지침이 있는 정책이 많은 환경을 탐색해야 하거나, 각 단계가 이전 단계를 기반으로 하고 실수의 비용이 큰 순차적 의사 결정을 해야 할 때 더 적합합니다.
다음은 τ-Bench에서 제공하는 표준 도구 사양 형식을 사용한 샘플 구현입니다:
{
"name": "think",
"description": "Use the tool to think about something. It will not obtain new information or change the database, but just append the thought to the log. Use it when complex reasoning or some cache memory is needed.",
"input_schema": {
"type": "object",
"properties": {
"thought": {
"type": "string",
"description": "A thought to think about."
}
},
"required": ["thought"]
}
}
τ-Bench에서의 성능
우리는 현실적인 고객 서비스 시나리오에서 모델의 도구 사용 능력을 테스트하도록 설계된 포괄적인 벤치마크인 τ-bench (tau-bench)를 사용하여 "think" 도구를 평가했습니다. 여기서 "think" 도구는 평가의 표준 환경의 일부입니다.
τ-bench는 Claude의 다음 능력을 평가합니다:
- 시뮬레이션된 사용자와의 현실적인 대화 탐색
- 복잡한 고객 서비스 에이전트 정책 지침을 일관되게 따르기
- 환경 데이터베이스에 액세스하고 조작하기 위해 다양한 도구 사용
τ-bench에서 사용되는 주요 평가 지표는 pass^k로, 이는 주어진 작업에 대한 모든 k개의 독립적인 작업 시도가 성공할 확률을 측정하며, 모든 작업에 대해 평균을 냅니다. 다른 LLM 평가에서 일반적인 pass@k 지표(k번의 시도 중 적어도 하나가 성공하는지 측정)와 달리, pass^k는 일관성과 신뢰성을 평가합니다 - 이는 정책 준수의 일관성이 필수적인 고객 서비스 애플리케이션에서 중요한 품질입니다.
성능 분석
우리의 평가는 여러 가지 다른 구성을 비교했습니다:
- 기준선 (Baseline) ("think" 도구 없음, 확장된 사고 모드 없음)
- 확장된 사고 모드만 사용
- "Think" 도구만 사용
- 최적화된 프롬프트와 함께 "Think" 도구 사용 (항공 도메인용)
결과는 Claude 3.7이 벤치마크의 "항공" 및 "소매" 고객 서비스 도메인 모두에서 "think" 도구를 효과적으로 사용했을 때 극적인 개선을 보여주었습니다:
- 항공 도메인: 최적화된 프롬프트와 함께 "think" 도구는 pass^1 지표에서 0.570을 달성했으며, 기준선의 0.370과 비교하여 54%의 상대적 개선을 보였습니다.
- 소매 도메인: "think" 도구만으로 0.812를 달성했으며, 기준선의 0.783과 비교됩니다.
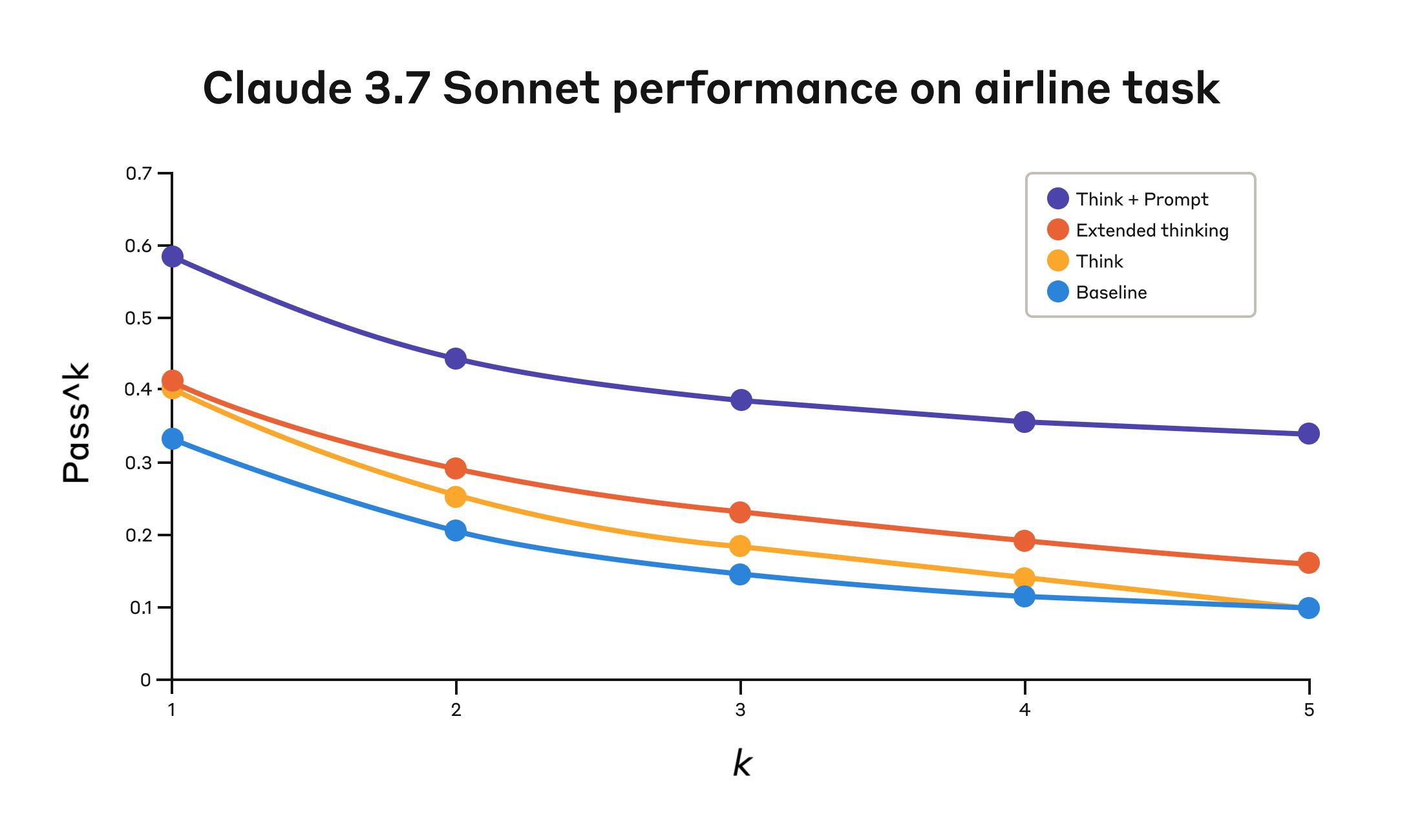
네 가지 다른 구성에서 Tau-Bench 평가의 "항공" 도메인에서 Claude 3.7 Sonnet의 성능.
Claude 3.7 Sonnet의 Tau-Bench 평가 "항공" 도메인 성능
| 구성 | k=1 | k=2 | k=3 | k=4 | k=5 |
|---|---|---|---|---|---|
| "Think" + 프롬프트 | 0.584 | 0.444 | 0.384 | 0.356 | 0.340 |
| "Think" | 0.404 | 0.254 | 0.186 | 0.140 | 0.100 |
| 확장된 사고 | 0.412 | 0.290 | 0.232 | 0.192 | 0.160 |
| 기준선 | 0.332 | 0.206 | 0.148 | 0.116 | 0.100 |
네 가지 다른 구성에서의 평가 결과. 점수는 비율입니다.
항공 도메인에서 최고의 성능은 고객 요청을 분석할 때 사용할 추론 접근법의 유형에 대한 예시를 제공하는 최적화된 프롬프트와 "think" 도구를 결합하여 달성되었습니다. 다음은 최적화된 프롬프트의 예입니다:
## Using the think tool
Before taking any action or responding to the user after receiving tool results, use the think tool as a scratchpad to:
- List the specific rules that apply to the current request
- Check if all required information is collected
- Verify that the planned action complies with all policies
- Iterate over tool results for correctness
Here are some examples of what to iterate over inside the think tool:
<think_tool_example_1>
User wants to cancel flight ABC123
- Need to verify: user ID, reservation ID, reason
- Check cancellation rules:
* Is it within 24h of booking?
* If not, check ticket class and insurance
- Verify no segments flown or are in the past
- Plan: collect missing info, verify rules, get confirmation
</think_tool_example_1>
<think_tool_example_2>
User wants to book 3 tickets to NYC with 2 checked bags each
- Need user ID to check:
* Membership tier for baggage allowance
* Which payments methods exist in profile
- Baggage calculation:
* Economy class × 3 passengers
* If regular member: 1 free bag each → 3 extra bags = $150
* If silver member: 2 free bags each → 0 extra bags = $0
* If gold member: 3 free bags each → 0 extra bags = $0
- Payment rules to verify:
* Max 1 travel certificate, 1 credit card, 3 gift cards
* All payment methods must be in profile
* Travel certificate remainder goes to waste
- Plan:
1. Get user ID
2. Verify membership level for bag fees
3. Check which payment methods in profile and if their combination is allowed
4. Calculate total: ticket price + any bag fees
5. Get explicit confirmation for booking
</think_tool_example_2>
특히 흥미로운 점은 다른 접근법들이 어떻게 비교되었는지입니다. 최적화된 프롬프트와 함께 "think" 도구를 사용하는 것이 확장된 사고 모드(프롬프트가 없는 "think" 도구와 유사한 성능을 보임)보다 훨씬 더 나은 결과를 달성했습니다. "think" 도구만 사용하는 것(프롬프트 없이)은 기준선보다 성능이 향상되었지만, 여전히 최적화된 접근법에는 미치지 못했습니다.
"think" 도구와 최적화된 프롬프트의 조합은 상당한 차이로 가장 강력한 성능을 제공했으며, 이는 벤치마크의 항공 정책 부분의 높은 복잡성 때문일 가능성이 높습니다. 여기서 모델은 "생각"하는 방법에 대한 예시를 제공받음으로써 가장 많은 이익을 얻었습니다.
소매 도메인에서도 각 접근법의 구체적인 영향을 이해하기 위해 다양한 구성을 테스트했습니다.
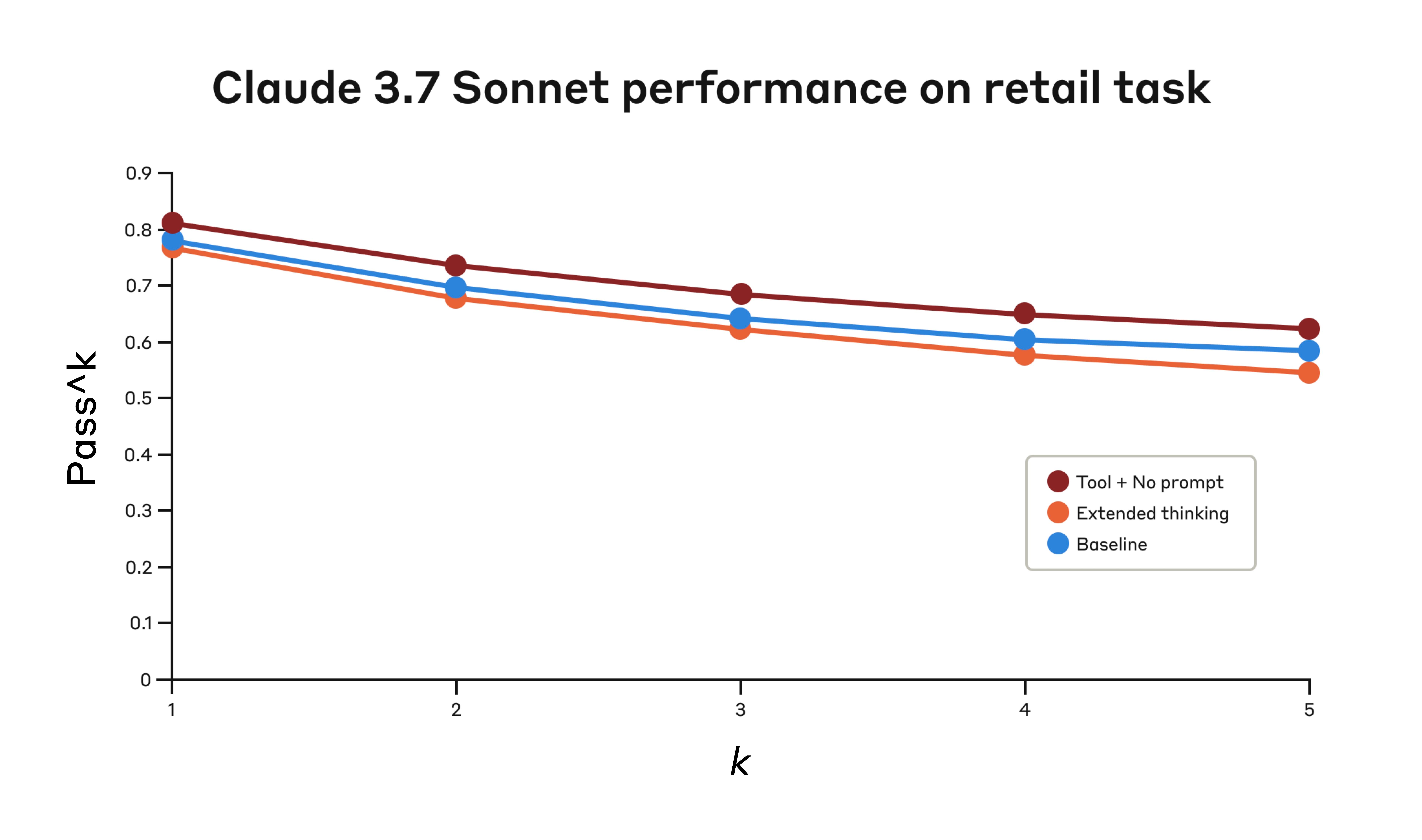
세 가지 다른 구성에서 Tau-Bench 평가의 "소매" 도메인에서 Claude 3.7 Sonnet의 성능.
Claude 3.7 Sonnet의 Tau-Bench 평가 "소매" 도메인 성능
| 구성 | k=1 | k=2 | k=3 | k=4 | k=5 |
|---|---|---|---|---|---|
| "Think" + 프롬프트 없음 | 0.812 | 0.735 | 0.685 | 0.650 | 0.626 |
| 확장된 사고 | 0.770 | 0.681 | 0.623 | 0.581 | 0.548 |
| 기준선 | 0.783 | 0.695 | 0.643 | 0.607 | 0.583 |
세 가지 다른 구성에서의 평가 결과. 점수는 비율입니다.
"think" 도구는 추가 프롬프트 없이도 가장 높은 pass^1 점수인 0.812를 달성했습니다. 소매 정책은 항공 도메인에 비해 탐색하기가 눈에 띄게 쉬우며, Claude는 추가 지침 없이 생각할 공간만 있어도 개선할 수 있었습니다.
τ-Bench 분석의 주요 통찰
우리의 상세한 분석은 "think" 도구를 효과적으로 구현하는 데 도움이 될 수 있는 몇 가지 패턴을 드러냈습니다:
- 어려운 도메인에서는 프롬프트가 매우 중요합니다. "think" 도구를 단순히 사용 가능하게 만드는 것만으로도 성능이 다소 향상될 수 있지만, 어려운 도메인의 경우 최적화된 프롬프트와 함께 사용하면 극적으로 더 나은 결과를 얻을 수 있습니다. 그러나 쉬운 도메인은 단순히 "think"에 액세스할 수 있는 것만으로도 이익을 얻을 수 있습니다.
- 시도 전반에 걸쳐 일관성이 향상되었습니다. "think" 사용으로 인한 개선은 k=5까지 pass^k에 대해 유지되었으며, 이는 도구가 Claude가 엣지 케이스와 비정상적인 시나리오를 더 효과적으로 처리하는 데 도움이 되었음을 나타냅니다.
SWE-Bench에서의 성능
Claude 3.7 Sonnet을 평가할 때 우리의 SWE-bench 설정에 유사한 "think" 도구가 추가되어 0.623의 최첨단 점수 달성에 기여했습니다. 적용된 "think" 도구 정의는 다음과 같습니다:
{
"name": "think",
"description": "Use the tool to think about something. It will not obtain new information or make any changes to the repository, but just log the thought. Use it when complex reasoning or brainstorming is needed. For example, if you explore the repo and discover the source of a bug, call this tool to brainstorm several unique ways of fixing the bug, and assess which change(s) are likely to be simplest and most effective. Alternatively, if you receive some test results, call this tool to brainstorm ways to fix the failing tests.",
"input_schema": {
"type": "object",
"properties": {
"thought": {
"type": "string",
"description": "Your thoughts."
}
},
"required": ["thought"]
}
}
우리의 실험("think" 도구가 있는 n=30 샘플, 없는 n=144 샘플)은 이 도구를 포함하는 것의 고립된 효과가 평균적으로 1.6%의 성능 향상을 보여주었습니다 (Welch's t-test: t(38.89) = 6.71, p< .001, d = 1.47).
"think" 도구를 사용해야 할 때
이러한 평가 결과를 바탕으로, 우리는 Claude가 "think" 도구로부터 가장 많은 이익을 얻는 특정 시나리오를 식별했습니다:
- 도구 출력 분석. Claude가 행동하기 전에 이전 도구 호출의 출력을 신중하게 처리해야 하고 접근 방식에서 되돌아가야 할 수도 있을 때
- 정책이 많은 환경. Claude가 상세한 지침을 따르고 준수를 확인해야 할 때
- 순차적 의사 결정. 각 행동이 이전 행동을 기반으로 하고 실수의 비용이 클 때 (종종 다단계 도메인에서 발견됨)
구현 모범 사례
τ-bench 실험을 기반으로 Claude와 함께 "think" 도구를 최대한 활용하려면 다음 구현 사례를 권장합니다.
1. 도메인별 예시를 통한 전략적 프롬프트
가장 효과적인 접근법은 τ-bench 항공 도메인에 사용된 것과 같이 "think" 도구를 언제 어떻게 사용해야 하는지에 대한 명확한 지침을 제공하는 것입니다. 특정 사용 사례에 맞게 조정된 예시를 제공하면 모델이 "think" 도구를 얼마나 효과적으로 사용하는지가 크게 향상됩니다:
- 추론 과정에서 예상되는 세부 사항 수준
- 복잡한 지침을 실행 가능한 단계로 분해하는 방법
- 일반적인 시나리오를 처리하기 위한 의사 결정 트리
- 필요한 모든 정보가 수집되었는지 확인하는 방법
2. 시스템 프롬프트에 복잡한 지침 배치
우리는 길고 복잡한 경우, "think" 도구에 대한 지침을 도구 설명 자체에 배치하는 것보다 시스템 프롬프트에 포함하는 것이 더 효과적이라는 것을 발견했습니다. 이 접근법은 더 넓은 컨텍스트를 제공하고 모델이 사고 과정을 전체 동작에 더 잘 통합하도록 돕습니다.
"think" 도구를 사용하지 않아야 할 때
"think" 도구가 상당한 개선을 제공할 수 있지만, 모든 도구 사용 사례에 적용 가능한 것은 아니며, 프롬프트 길이와 출력 토큰 증가의 비용이 발생합니다. 구체적으로, 우리는 다음 사용 사례에서 "think" 도구가 어떤 개선도 제공하지 않는다는 것을 발견했습니다:
- 비순차적 도구 호출. Claude가 작업을 완료하기 위해 단일 도구 호출 또는 여러 병렬 호출만 수행해야 하는 경우, "think"를 추가하여 개선될 가능성은 낮습니다.
- 간단한 지시 따르기. Claude가 준수해야 할 제약이 많지 않고 기본 동작이 충분히 좋을 때, 추가적인 "think"-ing으로 인한 이득은 없을 것입니다.
시작하기
"think" 도구는 몇 단계만으로 의미 있는 개선을 가져올 수 있는 Claude 구현에 대한 간단한 추가 사항입니다:
- 에이전틱 도구 사용 시나리오로 테스트하십시오. 도전적인 사용 사례부터 시작하십시오 - Claude가 현재 정책 준수나 긴 도구 호출 체인에서의 복잡한 추론에 어려움을 겪는 경우입니다.
- 도구 정의를 추가하십시오. 도메인에 맞게 사용자 정의된 "think" 도구를 구현하십시오. 최소한의 코드가 필요하지만 더 구조화된 추론을 가능하게 합니다. 또한 도구를 언제 어떻게 사용해야 하는지에 대한 지침을 시스템 프롬프트에 도메인과 관련된 예시와 함께 포함하는 것을 고려하십시오.
- 모니터링하고 개선하십시오. Claude가 실제로 도구를 사용하는 방법을 관찰하고, 더 효과적인 사고 패턴을 장려하도록 프롬프트를 조정하십시오.
가장 좋은 점은 이 도구를 추가하는 것이 성능 결과 측면에서 최소한의 단점이 있다는 것입니다. Claude가 사용하기로 결정하지 않는 한 외부 동작을 변경하지 않으며, 기존 도구나 워크플로우를 방해하지 않습니다.
결론
우리의 연구는 "think" 도구가 정책 준수와 긴 도구 호출 체인에서의 추론이 필요한 복잡한 작업에서 Claude 3.7 Sonnet의 성능¹을 크게 향상시킬 수 있음을 보여주었습니다. "Think"는 만능 솔루션은 아니지만, 올바른 사용 사례에 대해 상당한 이점을 제공하며, 모두 최소한의 구현 복잡성으로 가능합니다.
우리는 여러분이 "think" 도구를 사용하여 Claude와 함께 더 유능하고 신뢰할 수 있으며 투명한 AI 시스템을 구축하는 방법을 보게 되기를 기대합니다.
- τ-Bench 결과는 "think" 도구를 사용한 Claude 3.7 Sonnet의 개선에 초점을 맞췄지만, 우리의 실험은 Claude 3.5 Sonnet (New)도 3.7 Sonnet과 동일한 구성으로 성능 향상을 달성할 수 있음을 보여주며, 이는 이 개선이 다른 Claude 모델에도 일반화됨을 나타냅니다.
아래 내용은 독자의 이해를 돕기 위해 공부하우가 추가한 설명입니다. 원문에는 없는 내용입니다.
주요 용어 설명
이 문서에서 사용된 주요 기술 용어들을 설명합니다:
AI 도구 관련 용어
"think" 도구 ("think" tool)
Claude가 복잡한 작업을 수행할 때 중간에 멈추고 생각할 수 있는 공간을 제공하는 도구입니다. 이는 복잡한 문제를 해결하거나 여러 단계의 작업을 수행할 때 Claude의 성능을 향상시킵니다.
확장된 사고 (extended thinking)
Claude가 응답을 생성하기 전에 수행하는 깊은 사고 과정입니다. 이는 Claude가 행동을 취하기 전에 계획을 신중하게 고려하고 반복하는 과정을 말합니다.
에이전틱 도구 사용 (agentic tool use)
AI가 자율적으로 도구를 선택하고 사용하여 작업을 수행하는 능력을 말합니다. 이는 AI가 단순히 지시를 따르는 것이 아니라, 목표를 달성하기 위해 능동적으로 도구를 활용하는 것을 의미합니다.
벤치마크 관련 용어
τ-Bench (tau-bench)
현실적인 고객 서비스 시나리오에서 AI 모델의 도구 사용 능력을 테스트하기 위해 설계된 포괄적인 벤치마크입니다. 실제 업무 환경과 유사한 상황에서 AI의 성능을 평가합니다.
SWE-Bench
소프트웨어 엔지니어링 작업에서 AI의 성능을 평가하는 벤치마크입니다. 코드 작성, 버그 수정, 테스트 작성 등의 실제 프로그래밍 작업을 수행하는 능력을 측정합니다.
pass^k 지표
모든 k개의 독립적인 시도가 성공할 확률을 측정하는 지표입니다. 이는 AI의 일관성과 신뢰성을 평가하는 데 사용되며, 특히 정책 준수가 중요한 고객 서비스 애플리케이션에서 중요합니다.
기술 구현 관련 용어
시스템 프롬프트 (system prompt)
AI 모델에게 전반적인 동작 방식과 지침을 제공하는 초기 설정 메시지입니다. 이는 모델이 사용자와 상호작용하는 방식을 결정하는 중요한 요소입니다.
도구 호출 체인 (tool call chains)
여러 도구를 순차적으로 호출하여 복잡한 작업을 수행하는 과정입니다. 각 도구의 출력이 다음 도구의 입력이 되는 연결된 작업 흐름을 의미합니다.
구현 오버헤드 (implementation overhead)
새로운 기능이나 도구를 구현하는 데 필요한 추가적인 작업량이나 복잡성을 의미합니다. 낮은 구현 오버헤드는 쉽고 빠르게 적용할 수 있음을 나타냅니다.