📄 원문: Introducing Claude 4
- 출처: Introducing Claude 4
- 저자: Anthropic
- 원문 발행일: 2025년 5월 14일
- 라이선스: 저작권 Anthropic - 번역 허가 미확인
- 번역일: 2025년 5월 30일
- 번역 및 감수: Claude and 공부하우
⚖️ 저작권 안내
이 번역문은 교육 및 정보 제공 목적으로 작성되었습니다. 원문의 저작권은 Anthropic에 있으며, 이 번역은 Anthropic의 공식 번역이 아닙니다.
본 번역은 다음과 같은 교육적 공정 사용(Fair Use) 원칙에 따라 제공됩니다:
- 비영리 교육 목적
- 원문 출처의 명확한 표시
- 한국어 사용자의 기술 이해 증진을 위한 변형적 사용
- 원저작물의 시장 가치에 부정적 영향을 미치지 않음
저작권 관련 문제가 제기될 경우, 즉시 적절한 조치를 취하겠습니다. 상업적 사용이나 재배포 전에 원저작권자의 허가를 받으시기 바랍니다.
문의사항이나 우려사항이 있으시면 오른쪽 템플릿 복사를 클릭 하신 뒤, 연락 페이지를 통해 알려 주시기 바랍니다.
Claude 4 소개
오늘 우리는 차세대 Claude 모델을 소개합니다: Claude Opus 4와 Claude Sonnet 4는 코딩, 고급 추론, 그리고 AI 에이전트 (AI agents)에서 새로운 기준을 제시합니다.
Claude Opus 4는 세계 최고의 코딩 모델로, 복잡하고 장기간 실행되는 작업과 에이전트 워크플로우에서 지속적인 성능을 발휘합니다. Claude Sonnet 4는 Claude Sonnet 3.7의 중요한 업그레이드로, 우수한 코딩과 추론 능력을 제공하면서 사용자의 지시에 더 정확하게 응답합니다.
모델과 함께 다음도 발표합니다:
- 도구 사용을 통한 확장 사고 (베타): 두 모델 모두 확장 사고 중에 웹 검색과 같은 도구를 사용할 수 있어, Claude가 추론과 도구 사용을 번갈아가며 응답을 개선할 수 있습니다.
- 새로운 모델 기능: 두 모델 모두 도구를 병렬로 사용하고, 지시사항을 더 정확하게 따르며, 개발자가 로컬 파일 접근 권한을 부여하면 크게 향상된 메모리 기능을 보여줍니다. 핵심 사실을 추출하고 저장하여 연속성을 유지하고 시간이 지남에 따라 암묵적 지식 (tacit knowledge)을 구축합니다.
- Claude Code가 이제 일반 공개됩니다: 연구 프리뷰 기간 동안 광범위한 긍정적 피드백을 받은 후, 개발자가 Claude와 협업할 수 있는 방법을 확장합니다. Claude Code는 이제 GitHub Actions를 통한 백그라운드 작업과 VS Code 및 JetBrains의 네이티브 통합을 지원하여, 원활한 페어 프로그래밍 (pair programming)을 위해 편집 내용을 파일에 직접 표시합니다.
- 새로운 API 기능: 우리는 개발자가 더 강력한 AI 에이전트를 구축할 수 있도록 하는 네 가지 새로운 기능을 Anthropic API에 출시합니다: 코드 실행 도구, MCP 커넥터 (MCP connector), Files API, 그리고 최대 1시간 동안 프롬프트를 캐시하는 기능입니다.
Claude Opus 4와 Sonnet 4는 두 가지 모드를 제공하는 하이브리드 모델 (hybrid models)입니다: 즉각적인 응답과 더 깊은 추론을 위한 확장 사고. Pro, Max, Team, Enterprise Claude 플랜에는 두 모델과 확장 사고가 모두 포함되며, Sonnet 4는 무료 사용자도 이용할 수 있습니다. 두 모델 모두 Anthropic API, Amazon Bedrock, Google Cloud의 Vertex AI에서 사용할 수 있습니다. 가격은 이전 Opus 및 Sonnet 모델과 동일하게 유지됩니다: Opus 4는 백만 토큰당 $15/$75 (입력/출력), Sonnet 4는 $3/$15입니다.
Claude 4
Claude Opus 4는 우리의 가장 강력한 모델이자 세계 최고의 코딩 모델로, SWE-bench (72.5%)와 Terminal-bench (43.2%)에서 선두를 달리고 있습니다. 집중적인 노력과 수천 단계가 필요한 장기간 작업에서 지속적인 성능을 제공하며, 몇 시간 동안 지속적으로 작업할 수 있는 능력으로 모든 Sonnet 모델을 크게 능가하고 AI 에이전트가 달성할 수 있는 것을 크게 확장합니다.
Claude Opus 4는 코딩과 복잡한 문제 해결에 탁월하며, 최첨단 에이전트 제품을 구동합니다. Cursor는 이를 코딩을 위한 최신 기술이자 복잡한 코드베이스 (codebase) 이해의 도약이라고 부릅니다. Replit은 정밀도 향상과 여러 파일에 걸친 복잡한 변경에 대한 극적인 발전을 보고합니다. Block은 에이전트 _codename goose_에서 편집 및 디버깅 중 코드 품질을 향상시킨 첫 번째 모델이라고 부르며, 전체 성능과 신뢰성을 유지합니다. Rakuten은 7시간 동안 독립적으로 실행되는 까다로운 오픈 소스 리팩터링으로 지속적인 성능과 함께 그 기능을 검증했습니다. Cognition은 Opus 4가 다른 모델이 할 수 없는 복잡한 문제를 해결하는 데 탁월하며, 이전 모델이 놓친 중요한 작업을 성공적으로 처리한다고 언급합니다.
Claude Sonnet 4는 Sonnet 3.7의 업계 선도적인 기능을 크게 개선하여, SWE-bench에서 최첨단 72.7%의 코딩 성능을 발휘합니다. 이 모델은 내부 및 외부 사용 사례에 대한 성능과 효율성의 균형을 맞추며, 구현에 대한 더 큰 제어를 위해 향상된 조종성 (steerability)을 제공합니다. 대부분의 영역에서 Opus 4와 일치하지는 않지만, 능력과 실용성의 최적 조합을 제공합니다.
GitHub은 Claude Sonnet 4가 에이전틱 시나리오 (agentic scenarios)에서 뛰어나며 GitHub Copilot의 새로운 코딩 에이전트를 구동하는 모델로 도입할 것이라고 말합니다. Manus는 복잡한 지시사항 따르기, 명확한 추론 및 미적 출력의 개선을 강조합니다. iGent는 Sonnet 4가 자율적인 다중 기능 앱 개발에서 탁월하며, 문제 해결 및 코드베이스 탐색이 크게 개선되어 탐색 오류가 20%에서 거의 0으로 감소했다고 보고합니다. Sourcegraph는 이 모델이 소프트웨어 개발에서 실질적인 도약으로서 가능성을 보여준다고 말합니다 - 더 오래 집중하고, 문제를 더 깊이 이해하며, 더 우아한 코드 품질을 제공합니다. Augment Code는 더 높은 성공률, 더 정밀한 코드 편집, 복잡한 작업을 통한 더 신중한 작업을 보고하며, 이를 주요 모델의 최고 선택으로 만듭니다.
이러한 모델은 고객의 AI 전략을 전반적으로 발전시킵니다: Opus 4는 코딩, 연구, 작문 및 과학적 발견의 경계를 넓히고, Sonnet 4는 Sonnet 3.7의 즉각적인 업그레이드로서 일상적인 사용 사례에 최첨단 성능을 제공합니다.
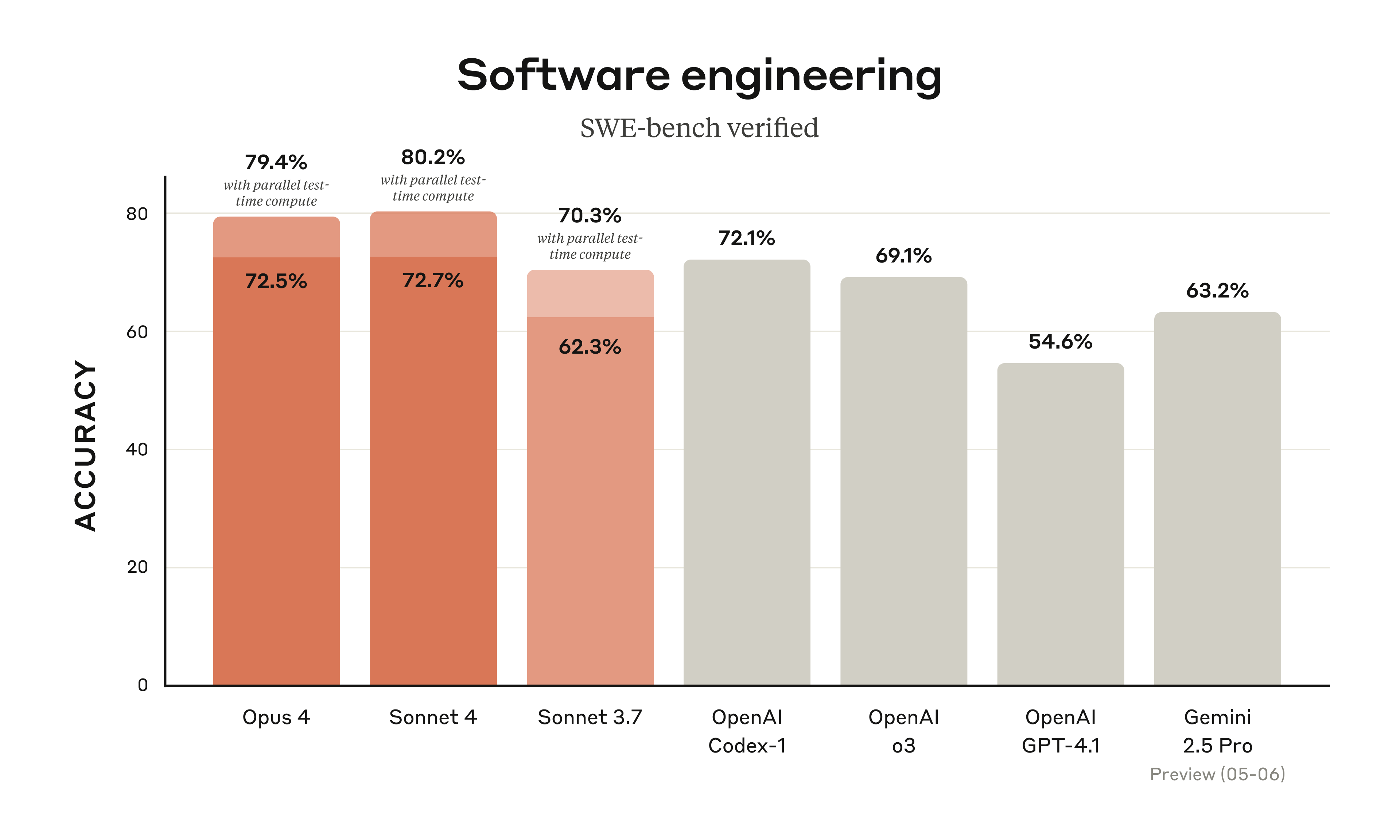
Claude 4 모델은 실제 소프트웨어 엔지니어링 작업 성능을 측정하는 벤치마크인 SWE-bench Verified에서 선두를 달리고 있습니다. 방법론에 대한 자세한 내용은 부록을 참조하세요.
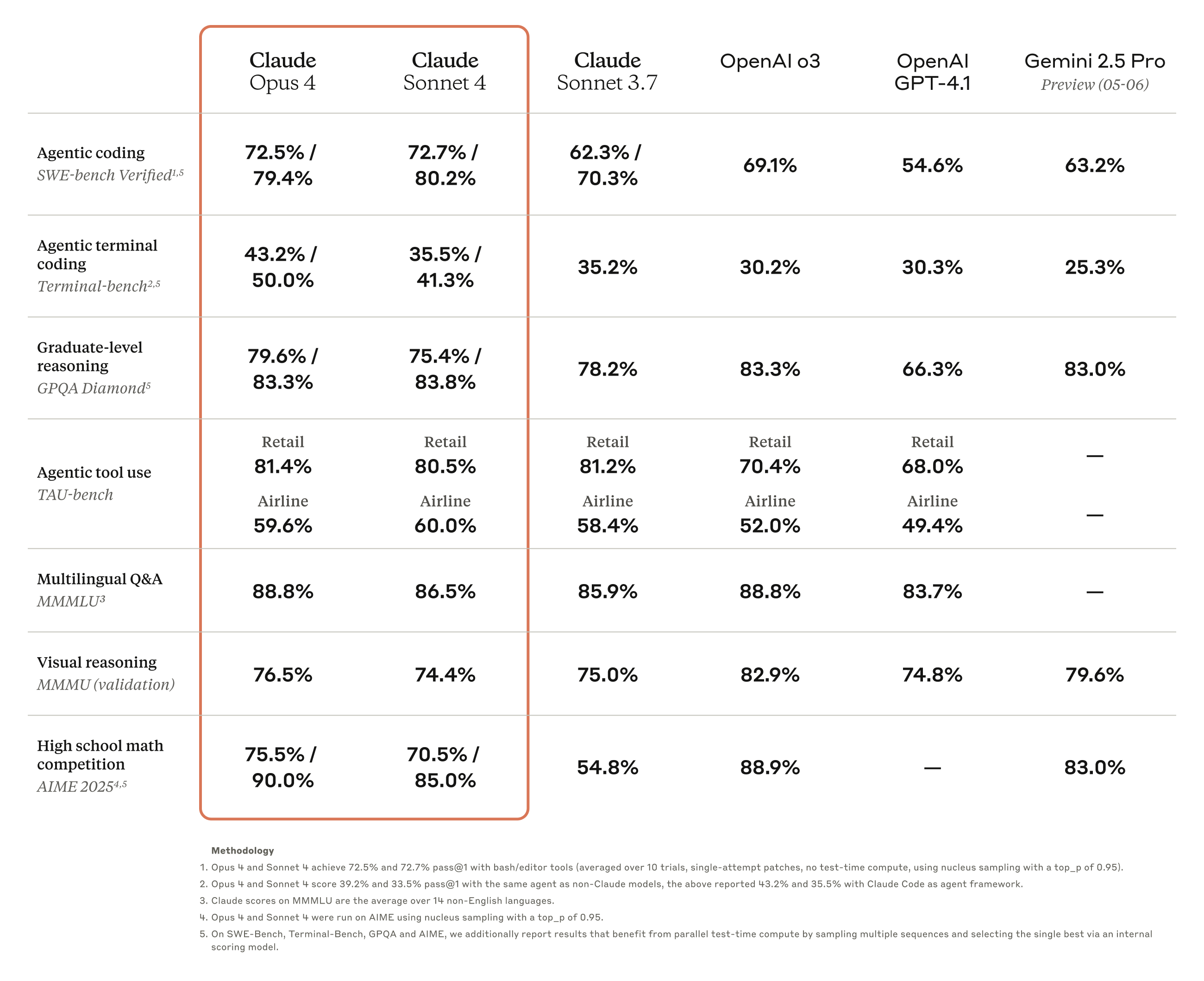
Claude 4 모델은 코딩, 추론, 멀티모달 기능 (multimodal capabilities) 및 에이전틱 작업 전반에 걸쳐 강력한 성능을 제공합니다. 방법론에 대한 자세한 내용은 부록을 참조하세요.
모델 개선사항
도구 사용을 통한 확장 사고, 병렬 도구 실행 및 메모리 개선 외에도, 모델이 작업을 완료하기 위해 단축키 (shortcuts)나 허점 (loopholes)을 사용하는 행동을 크게 줄였습니다. 두 모델 모두 단축키와 허점에 특히 취약한 에이전틱 작업에서 Sonnet 3.7보다 이러한 행동을 할 가능성이 65% 낮습니다.
Claude Opus 4는 또한 메모리 기능에서 모든 이전 모델을 크게 능가합니다. 개발자가 Claude에게 로컬 파일 접근 권한을 제공하는 애플리케이션을 구축할 때, Opus 4는 핵심 정보를 저장하기 위해 '메모리 파일'을 만들고 유지하는 데 능숙해집니다. 이는 더 나은 장기 작업 인식, 일관성 및 에이전트 작업 성능을 가능하게 합니다 - 예를 들어 Opus 4가 포켓몬을 플레이하는 동안 '내비게이션 가이드'를 만드는 것처럼요.
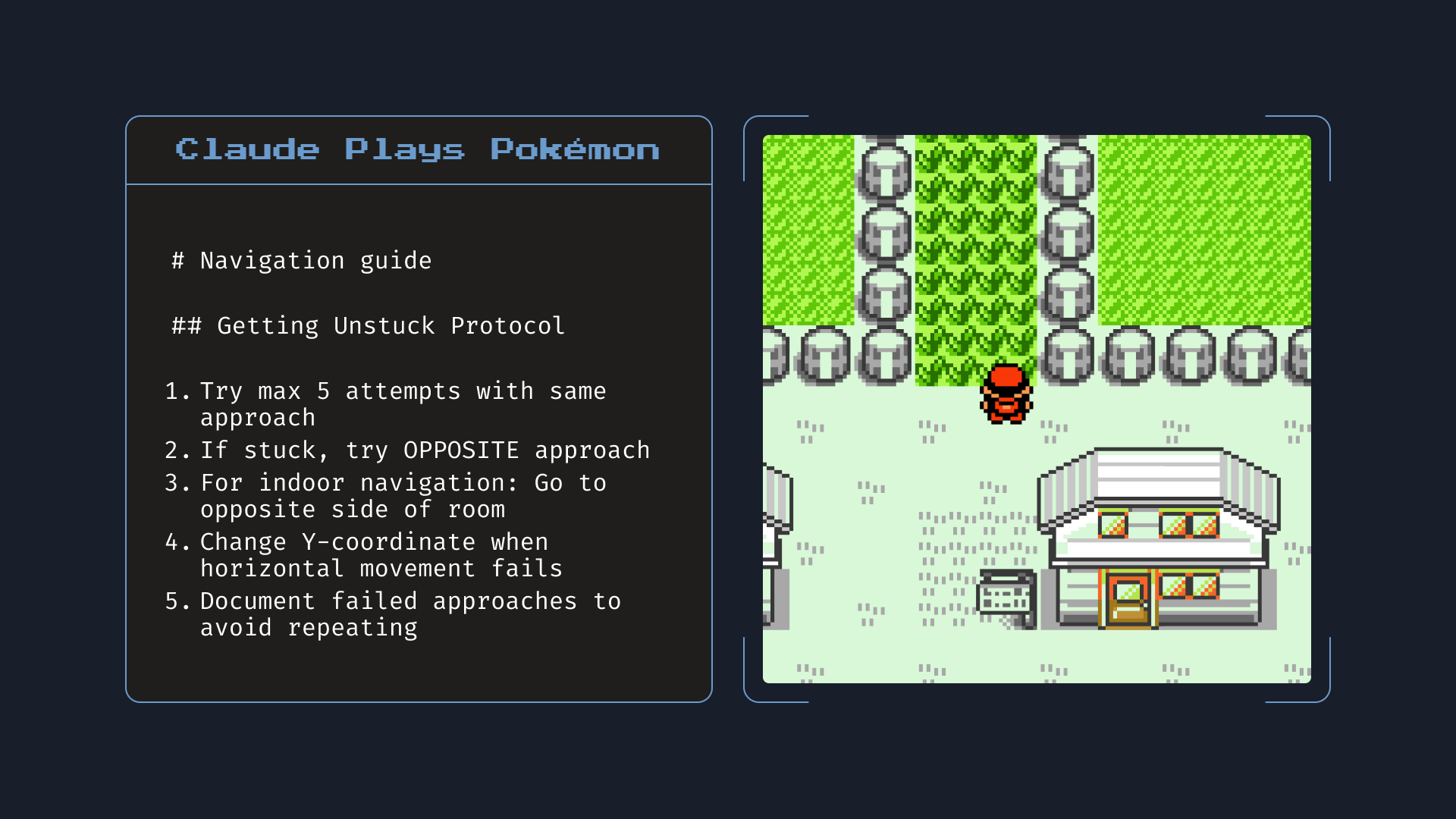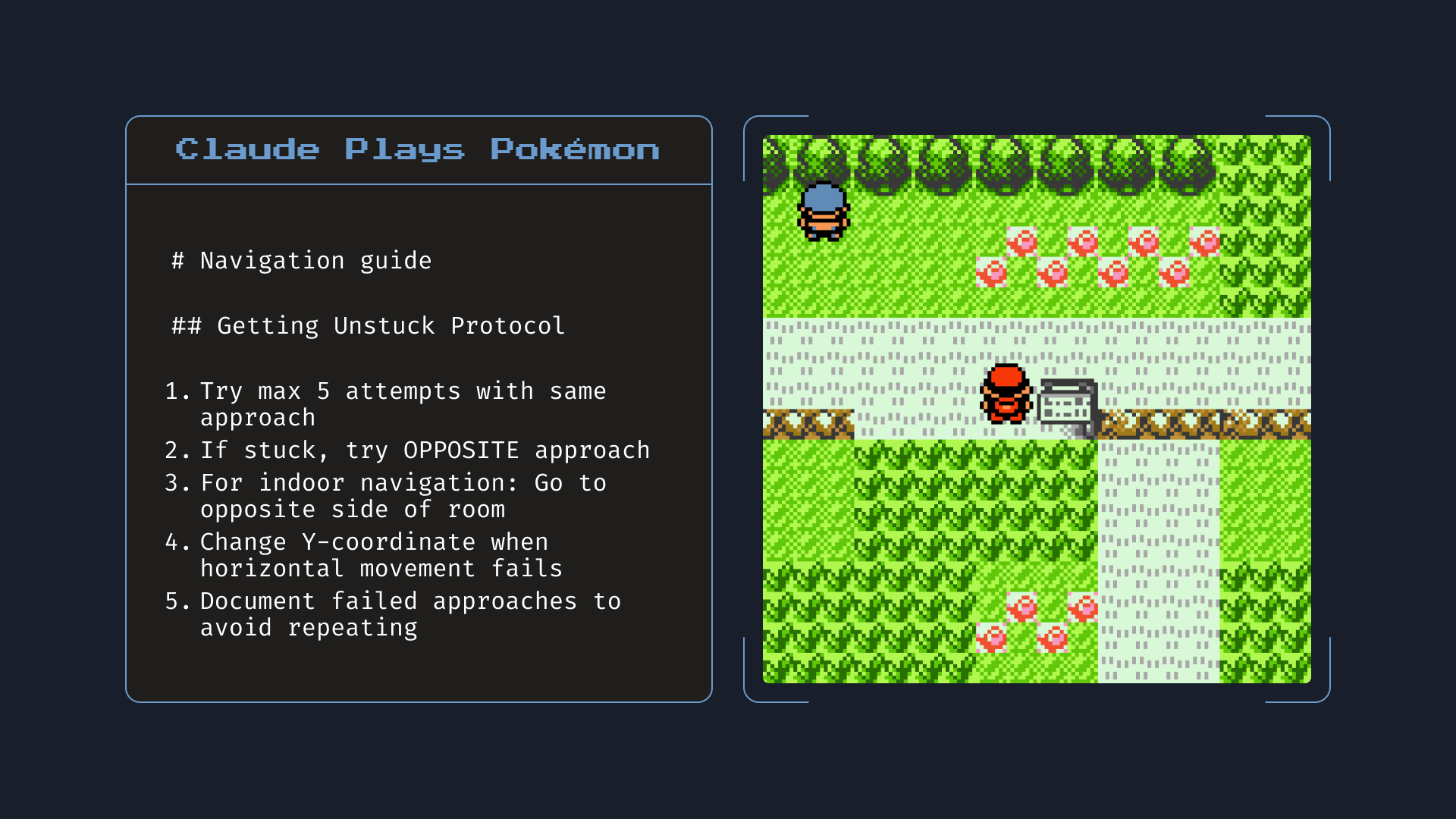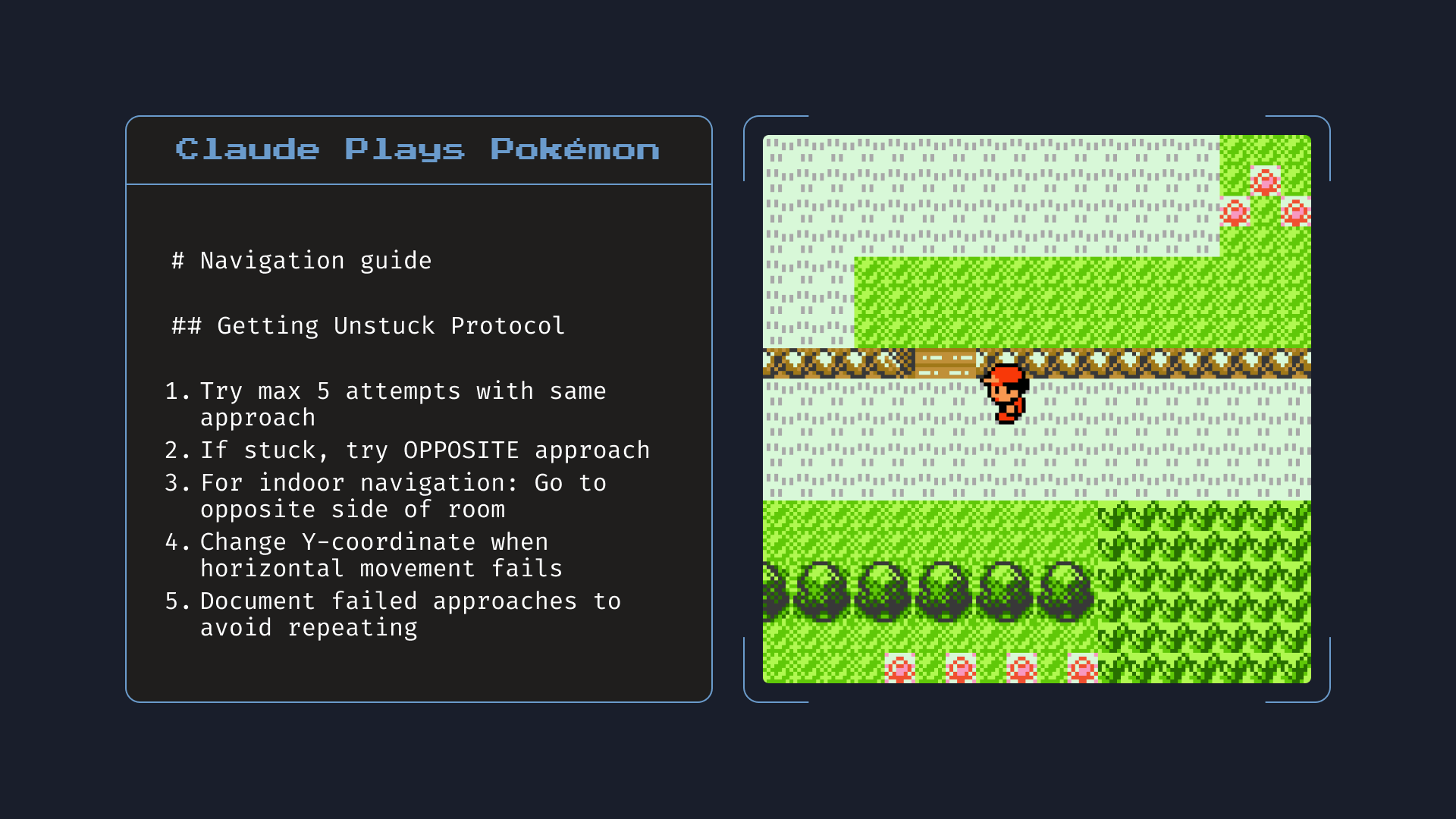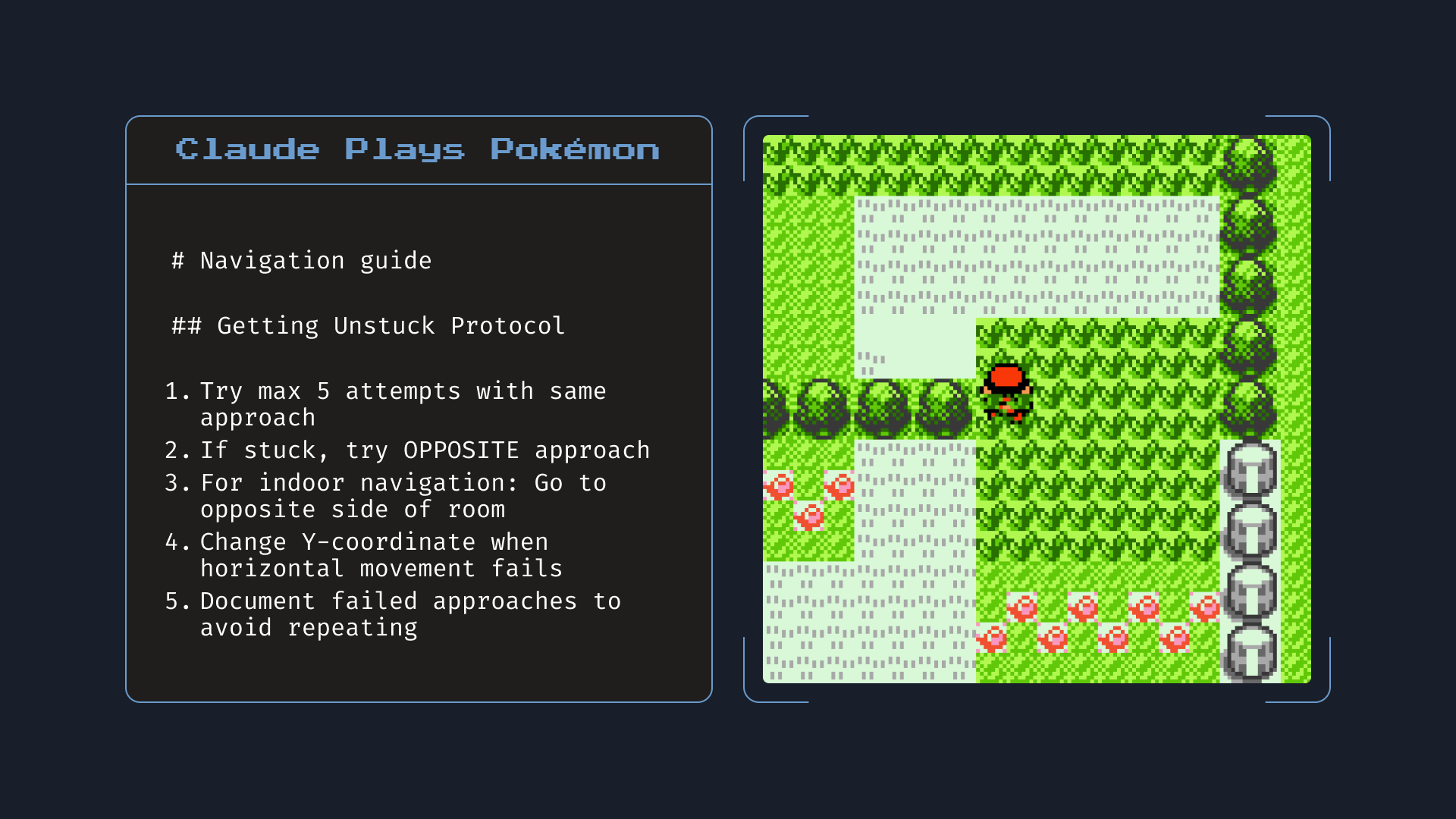
메모리: 로컬 파일에 대한 접근 권한이 주어지면, Claude Opus 4는 게임 플레이를 개선하는 데 도움이 되는 핵심 정보를 기록합니다. 위에 표시된 노트는 Opus 4가 포켓몬을 플레이하는 동안 작성한 실제 노트입니다.
마지막으로, 우리는 더 작은 모델을 사용하여 긴 사고 과정을 압축하는 Claude 4 모델의 사고 요약 (thinking summaries)을 도입했습니다. 이 요약은 약 5%의 경우에만 필요합니다 - 대부분의 사고 과정은 전체를 표시할 수 있을 만큼 짧습니다. 고급 프롬프트 엔지니어링 (prompt engineering)을 위해 원시 사고 체인이 필요한 사용자는 전체 접근을 유지하기 위해 새로운 개발자 모드에 대해 영업팀에 문의할 수 있습니다.
Claude Code
이제 일반 공개된 Claude Code는 Claude의 강력함을 더 많은 개발 워크플로우에 제공합니다 - 터미널, 좋아하는 IDE, 그리고 Claude Code SDK와 함께 백그라운드에서 실행됩니다.
VS Code와 JetBrains용 새로운 베타 확장 프로그램은 Claude Code를 IDE에 직접 통합합니다. Claude가 제안한 편집 내용이 파일에 인라인으로 표시되어 익숙한 편집기 인터페이스 내에서 검토 및 추적을 간소화합니다. IDE 터미널에서 Claude Code를 실행하기만 하면 설치됩니다.
IDE를 넘어, 우리는 확장 가능한 Claude Code SDK를 출시하여, Claude Code와 동일한 핵심 에이전트를 사용하여 자체 에이전트와 애플리케이션을 구축할 수 있습니다. 또한 SDK로 가능한 것의 예시를 출시합니다: 이제 베타 버전인 GitHub의 Claude Code. PR (Pull Request)에서 Claude Code를 태그하여 리뷰어 피드백에 응답하거나, CI (Continuous Integration) 오류를 수정하거나, 코드를 수정할 수 있습니다. 설치하려면 Claude Code 내에서 /install-github-app을 실행하세요.
시작하기
이러한 모델은 전체 컨텍스트를 유지하고, 더 긴 프로젝트에 집중을 유지하며, 변혁적인 영향을 주도하는 가상 협력자를 향한 큰 발걸음입니다. 이들은 위험을 최소화하고 안전을 최대화하기 위한 광범위한 테스트와 평가와 함께 제공되며, ASL-3과 같은 더 높은 AI 안전 수준 (AI Safety Levels)을 위한 조치 구현을 포함합니다.
우리는 여러분이 무엇을 만들지 기대가 됩니다. 오늘 Claude, Claude Code 또는 선택한 플랫폼에서 시작하세요.
언제나 그렇듯이, 여러분의 피드백은 우리가 개선하는 데 도움이 됩니다.
부록
성능 벤치마크 데이터 소스
- Open AI: o3 런치 포스트, o3 시스템 카드, GPT-4.1 런치 포스트, GPT-4.1 호스팅 평가
- Gemini: Gemini 2.5 Pro Preview 모델 카드
- Claude: Claude 3.7 Sonnet 런치 포스트
성능 벤치마크 보고
Claude Opus 4와 Sonnet 4는 하이브리드 추론 모델입니다. 이 블로그 포스트에 보고된 벤치마크는 확장 사고를 사용하거나 사용하지 않고 달성한 최고 점수를 보여줍니다. 각 결과에 대해 확장 사고가 사용되었는지 아래에 표시했습니다:
- 확장 사고 없음: SWE-bench Verified, Terminal-bench
- 확장 사고 (최대 64K 토큰):
- TAU-bench (확장 사고 없는 결과는 보고되지 않음)
- GPQA Diamond (확장 사고 없음: Opus 4는 74.9%, Sonnet 4는 70.0% 득점)
- MMMLU (확장 사고 없음: Opus 4는 87.4%, Sonnet 4는 85.4% 득점)
- MMMU (확장 사고 없음: Opus 4는 73.7%, Sonnet 4는 72.6% 득점)
- AIME (확장 사고 없음: Opus 4는 33.9%, Sonnet 4는 33.1% 득점)
TAU-bench 방법론
점수는 항공사 및 소매 에이전트 정책 모두에 프롬프트 부록을 추가하여 달성되었으며, Claude가 도구 사용과 함께 확장 사고를 사용하는 동안 추론 능력을 더 잘 활용하도록 지시합니다. 모델은 추론 능력을 최대한 활용하기 위해 다중 턴 궤적 동안 일반적인 사고 모드와는 별개로 문제를 해결하면서 생각을 기록하도록 권장됩니다. Claude가 더 많은 사고를 활용함으로써 발생하는 추가 단계를 수용하기 위해, 최대 단계 수(모델 완성으로 계산)는 30에서 100으로 증가했습니다 (대부분의 궤적은 30단계 미만으로 완료되었으며 50단계를 초과한 궤적은 하나뿐이었습니다).
SWE-bench 방법론
Claude 4 모델 계열의 경우, 우리는 이전 릴리스 여기에 설명된 두 가지 도구만 장착한 동일한 간단한 스캐폴드를 계속 사용합니다 - bash 도구와 문자열 교체를 통해 작동하는 파일 편집 도구입니다. 우리는 더 이상 Claude 3.7 Sonnet에서 사용된 세 번째 '계획 도구'를 포함하지 않습니다. 모든 Claude 4 모델에서 전체 500개 문제에 대한 점수를 보고합니다. OpenAI 모델의 점수는 477개 문제 하위 집합에서 보고됩니다.
"높은 컴퓨팅" 수치를 위해 다음과 같이 추가적인 복잡성과 병렬 테스트 시간 컴퓨팅을 채택합니다:
- 여러 병렬 시도를 샘플링합니다.
- 저장소의 가시적인 회귀 테스트를 깨뜨리는 패치를 폐기합니다. 이는 Agentless (Xia et al. 2024)에서 채택한 거부 샘플링 접근 방식과 유사합니다; 숨겨진 테스트 정보는 사용되지 않습니다.
- 그런 다음 내부 점수 모델을 사용하여 나머지 시도 중에서 최상의 후보를 선택합니다.
이 결과 Opus 4와 Sonnet 4는 각각 79.4%와 80.2%의 점수를 얻었습니다.
아래 내용은 독자의 이해를 돕기 위해 공부하우가 추가한 설명입니다. 원문에는 없는 내용입니다.
주요 용어 설명
이 문서에서 사용된 주요 기술 용어들을 설명합니다:
AI 및 모델 관련 용어
AI 에이전트 (AI agents)
특정 작업을 자율적으로 수행할 수 있는 AI 시스템입니다. 사용자의 목표를 이해하고, 필요한 단계를 계획하며, 도구를 사용하여 작업을 완료할 수 있는 지능형 프로그램입니다.
하이브리드 모델 (hybrid models)
두 가지 이상의 작동 모드를 가진 AI 모델입니다. Claude 4의 경우, 빠른 응답 모드와 깊은 사고를 위한 확장 사고 모드를 모두 제공합니다.
멀티모달 기능 (multimodal capabilities)
텍스트뿐만 아니라 이미지, 오디오 등 여러 형태의 입력을 처리할 수 있는 AI의 능력입니다.
조종성 (steerability)
AI 모델이 사용자의 지시사항을 얼마나 잘 따르고, 원하는 방향으로 출력을 조정할 수 있는지를 나타내는 특성입니다.
개발 관련 용어
코드베이스 (codebase)
특정 소프트웨어 프로젝트나 애플리케이션을 구성하는 전체 소스 코드의 집합입니다.
페어 프로그래밍 (pair programming)
두 명의 프로그래머가 하나의 컴퓨터에서 함께 코드를 작성하는 개발 방법론입니다. Claude Code의 경우, AI가 프로그래머의 파트너 역할을 합니다.
GitHub Actions
GitHub에서 제공하는 자동화 플랫폼으로, 코드 변경 시 자동으로 테스트, 빌드, 배포 등의 작업을 수행할 수 있습니다.
PR (Pull Request)
코드 변경사항을 메인 프로젝트에 병합하기 전에 검토를 요청하는 GitHub의 기능입니다.
CI (Continuous Integration)
개발자들이 코드를 자주 통합하고, 각 통합마다 자동 빌드와 테스트를 실행하여 문제를 빠르게 발견하는 개발 방법입니다.
기술적 개념
암묵적 지식 (tacit knowledge)
명시적으로 표현하기 어려운, 경험을 통해 습득되는 지식입니다. AI가 반복적인 작업을 통해 학습하는 패턴이나 노하우를 말합니다.
프롬프트 엔지니어링 (prompt engineering)
AI 모델로부터 원하는 결과를 얻기 위해 입력 프롬프트를 최적화하는 기술입니다.
에이전틱 시나리오 (agentic scenarios)
AI가 독립적으로 의사결정을 내리고 작업을 수행하는 상황을 말합니다. 단순한 질의응답을 넘어 복잡한 작업을 자율적으로 처리하는 시나리오입니다.
MCP 커넥터 (MCP connector)
Model Context Protocol의 약자로, AI 모델이 외부 시스템과 상호작용할 수 있게 해주는 연결 도구입니다.
벤치마크 관련 용어
SWE-bench
소프트웨어 엔지니어링 작업에서 AI 모델의 성능을 평가하는 벤치마크로, 실제 GitHub 이슈를 해결하는 능력을 측정합니다.
Terminal-bench
터미널 환경에서 AI 모델이 명령어를 사용하여 작업을 수행하는 능력을 평가하는 벤치마크입니다.
보안 관련 용어
AI 안전 수준 (AI Safety Levels)
AI 시스템의 잠재적 위험을 평가하고 관리하기 위한 프레임워크입니다. ASL-3는 더 높은 수준의 안전 조치가 필요한 AI 시스템을 나타냅니다.
단축키 (shortcuts) / 허점 (loopholes)
AI가 작업을 완료하기 위해 의도하지 않은 방법이나 부적절한 경로를 사용하는 행동을 말합니다. 예를 들어, 실제로 문제를 해결하지 않고 겉으로만 해결한 것처럼 보이게 하는 행동입니다.