📄 원문: Introducing Claude Sonnet 4.5
- 출처: Introducing Claude Sonnet 4.5
- 저자: Anthropic
- 원문 발행일: 2025년 9월 29일
- 라이선스: © 2025 Anthropic. All rights reserved.
- 번역일: 2025년 9월 29일
- 번역 및 감수: Claude and 공부하우
⚖️ 저작권 안내
이 번역문은 교육 및 정보 제공 목적으로 작성되었습니다. 원문의 저작권은 Anthropic에 있으며, 이 번역은 Anthropic의 공식 번역이 아닙니다.
본 번역은 다음과 같은 교육적 공정 사용(Fair Use) 원칙에 따라 제공됩니다:
- 비영리 교육 목적
- 원문 출처의 명확한 표시
- 한국어 사용자의 기술 이해 증진을 위한 변형적 사용
- 원저작물의 시장 가치에 부정적 영향을 미치지 않음
저작권 관련 문제가 제기될 경우, 즉시 적절한 조치를 취하겠습니다. 상업적 사용이나 재배포 전에 원저작권자의 허가를 받으시기 바랍니다.
문의사항이나 우려사항이 있으시면 오른쪽 템플릿 복사를 클릭 하신 뒤, 연락 페이지를 통해 알려 주시기 바랍니다.
Claude Sonnet 4.5 소개
Claude Sonnet 4.5는 세계 최고의 코딩 모델입니다. 복잡한 에이전트를 구축하는 데 가장 강력한 모델이며, 컴퓨터를 사용하는 데 있어 최고의 모델입니다. 그리고 추론과 수학 능력에서 상당한 향상을 보여줍니다.
코드는 어디에나 있습니다. 여러분이 사용하는 모든 애플리케이션, 스프레드시트, 소프트웨어 도구를 실행합니다. 이러한 도구를 사용하고 어려운 문제를 해결하는 것이 현대 업무를 수행하는 방법입니다.
Claude Sonnet 4.5는 이를 가능하게 합니다. 우리는 이 모델을 제품에 대한 주요 업그레이드와 함께 출시합니다. Claude Code에서는 가장 많이 요청받았던 기능 중 하나인 체크포인트를 추가했습니다. 이를 통해 진행 상황을 저장하고 이전 상태로 즉시 롤백할 수 있습니다. 터미널 인터페이스를 새롭게 단장했고 네이티브 VS Code 확장을 제공합니다. Claude API에 새로운 컨텍스트 편집 기능과 메모리 도구를 추가하여 에이전트가 더 오래 실행되고 더 큰 복잡성을 처리할 수 있게 했습니다. Claude 앱에서는 코드 실행과 파일 생성(스프레드시트, 슬라이드, 문서)을 대화에 직접 추가했습니다. 그리고 지난달 대기자 명단에 등록한 Max 사용자들에게 Chrome용 Claude 확장 프로그램을 제공합니다.
또한 개발자들에게 Claude Code를 만드는 데 사용한 것과 동일한 구성 요소를 제공합니다. 우리는 이를 Claude Agent SDK라고 부릅니다. 우리의 최첨단 제품을 구동하고 잠재력을 최대한 발휘할 수 있게 하는 인프라를 이제 여러분도 사용하여 구축할 수 있습니다.
이것은 우리가 출시한 가장 정렬된 최첨단 모델로, 이전 Claude 모델에 비해 여러 정렬 영역에서 큰 개선을 보여줍니다.
Claude Sonnet 4.5는 오늘부터 모든 곳에서 사용할 수 있습니다. 개발자라면 Claude API를 통해 간단히 claude-sonnet-4-5를 사용하면 됩니다. 가격은 Claude Sonnet 4와 동일하게 백만 토큰당 $3/$15로 유지됩니다.
최첨단 지능
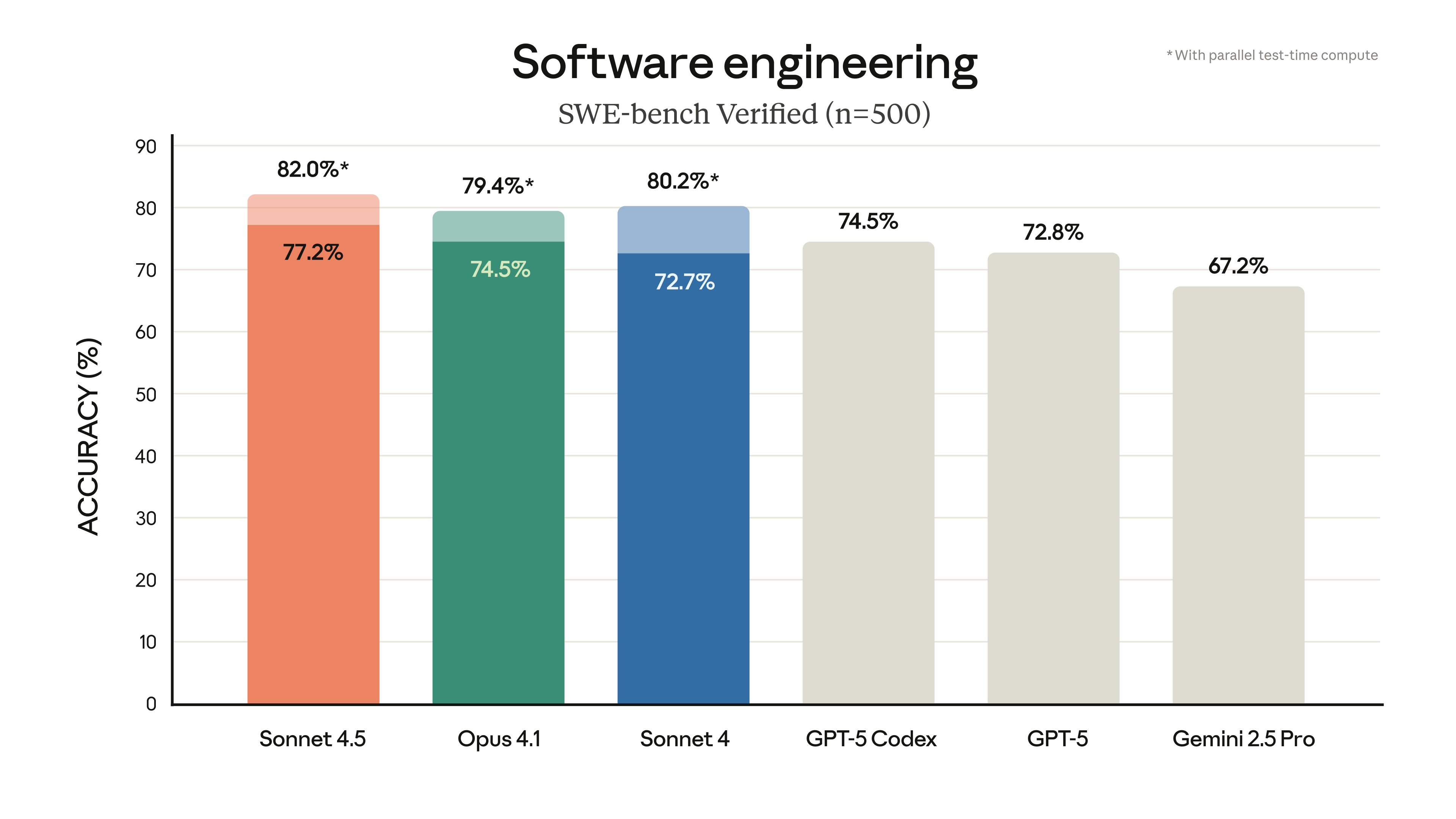
Claude Sonnet 4.5는 실제 소프트웨어 코딩 능력을 측정하는 SWE-bench Verified 평가에서 최첨단 성능을 보여줍니다. 실질적으로 우리는 이 모델이 복잡한 다단계 작업에서 30시간 이상 집중력을 유지하는 것을 관찰했습니다.
컴퓨터 사용 기능
Claude Sonnet 4.5는 컴퓨터 사용에서 상당한 도약을 나타냅니다. 실제 컴퓨터 작업에서 AI 모델을 테스트하는 벤치마크인 OSWorld에서 Sonnet 4.5는 현재 61.4%로 선두를 차지하고 있습니다. 불과 4개월 전 Sonnet 4는 42.2%로 선두를 유지했습니다. 우리의 Chrome용 Claude 확장 프로그램은 이러한 업그레이드된 기능을 활용합니다. 아래 데모에서 브라우저에서 직접 작업하고, 사이트를 탐색하고, 스프레드시트를 채우고, 작업을 완료하는 Claude를 보여드립니다.
광범위한 평가 개선
이 모델은 추론과 수학을 포함한 광범위한 평가에서도 향상된 기능을 보여줍니다:
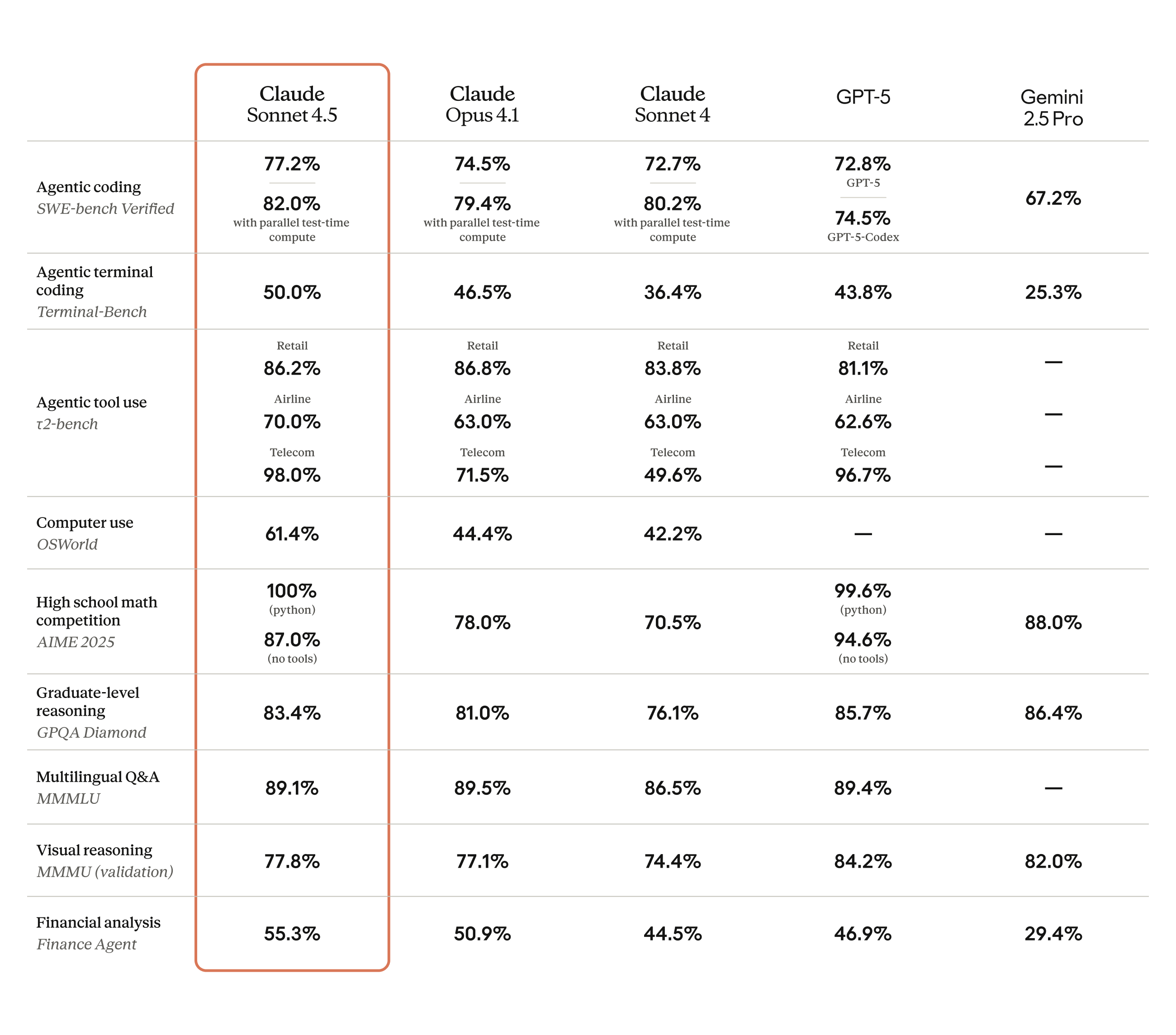
Claude Sonnet 4.5는 우리의 가장 강력한 모델입니다. 방법론은 각주를 참조하세요.
도메인별 전문 지식
금융, 법률, 의학, STEM 분야의 전문가들은 Sonnet 4.5가 Opus 4.1을 포함한 이전 모델에 비해 도메인별 지식과 추론이 극적으로 향상되었음을 확인했습니다.
고객 평가
이 모델의 기능은 초기 고객의 경험에서도 반영됩니다:
Cursor
Michael Truell, CEO
"우리는 Claude Sonnet 4.5에서 최첨단 코딩 성능을 보고 있으며, 장기 작업에서 상당한 개선을 확인했습니다. 이는 Cursor를 사용하는 많은 개발자가 가장 복잡한 문제를 해결하기 위해 Claude를 선택하는 이유를 더욱 강화합니다."
GitHub
Mario Rodriguez, Chief Product Officer
"Claude Sonnet 4.5는 GitHub Copilot의 핵심 강점을 증폭시킵니다. 우리의 초기 평가는 다단계 추론과 코드 이해에서 상당한 개선을 보여주며, Copilot의 에이전트 경험이 복잡하고 코드베이스 전반에 걸친 작업을 더 잘 처리할 수 있게 합니다."
Atlassian
Eric Wendelin, Tech Lead, GenAI for Developer Productivity
"Claude Sonnet 4.5는 소프트웨어 개발 작업에 탁월합니다. 우리 코드베이스 패턴을 학습하여 정확한 구현을 제공합니다. 디버깅부터 아키텍처까지 모든 것을 깊은 맥락적 이해로 처리하여 개발 속도를 변화시킵니다."
Vanta
Nidhi Aggarwal, Chief Product Officer
"Claude Sonnet 4.5는 Hai 보안 에이전트의 평균 취약점 처리 시간을 44% 단축하고 정확도를 25% 향상시켜 기업의 위험을 자신 있게 줄일 수 있도록 도와줍니다."
Thomson Reuters
Pablo Arredondo, Vice President, CoCounsel
"Claude Sonnet 4.5는 가장 복잡한 소송 작업에서 최첨단입니다. 예를 들어, 전체 브리핑 주기를 분석하고 판사를 위한 의견의 우수한 초안을 합성하기 위한 연구를 수행하거나, 전체 소송 기록을 검토하여 상세한 약식 판결 분석을 작성합니다."
Replit
Michele Catasta, President
"Claude Sonnet 4.5의 편집 기능은 탁월합니다 — Sonnet 4에서 9% 오류율이 **내부 코드 편집 벤치마크에서 0%**로 감소했습니다. 더 낮은 비용으로 더 높은 도구 성공률은 에이전트 코딩의 주요 도약입니다. Claude Sonnet 4.5는 창의성과 제어의 균형을 완벽하게 맞춥니다."
Canva
Danny Wu, Head of AI Products
"Claude Sonnet 4.5는 우리의 가장 복잡하고 긴 컨텍스트 작업에서 인상적인 성과를 제공합니다. 코드베이스의 엔지니어링부터 제품 내 기능 및 연구까지. 눈에 띄게 더 지능적이며 큰 도약으로, 2억 4천만 명 이상의 사용자가 Canva로 디자인할 수 있는 것을 확장하는 데 도움이 됩니다."
Figma
David Kossnick, Head of AI Products
"Claude Sonnet 4.5는 초기 테스트에서 Figma Make를 눈에 띄게 개선하여 프롬프트와 반복을 더 쉽게 만듭니다. 팀은 Figma가 알려진 디자인 품질을 유지하면서 더 기능적인 프로토타입과 더 부드러운 상호 작용으로 아이디어를 탐색하고 검증할 수 있습니다."
Poolside
Jeff Wang, CEO
"Sonnet 4.5는 새로운 세대의 코딩 모델을 나타냅니다. 예를 들어 여러 bash 명령을 한 번에 실행하는 것과 같이 병렬 도구 실행을 통해 컨텍스트 창당 작업을 최대화하는 데 놀라울 정도로 효율적입니다."
Cognition
Scott Wu, Co-Founder and CEO
"Devin의 경우, Claude Sonnet 4.5는 계획 성능을 18%, 엔드투엔드 평가 점수를 12% 증가시켰습니다. Claude Sonnet 3.6 출시 이후 가장 큰 도약입니다. 자체 코드 테스트에 탁월하여 Devin이 더 오래 실행되고 더 어려운 작업을 처리하며 프로덕션 준비 코드를 제공할 수 있게 합니다."
CrowdStrike
Sven Krasser, Sr. Vice President for Data Science and Chief Scientist
"Claude Sonnet 4.5는 레드 팀 활동에 강한 가능성을 보여줍니다. 공격자의 기술을 연구하는 방법을 가속화하는 창의적인 공격 시나리오를 생성합니다. 이러한 통찰력은 엔드포인트, ID, 클라우드, 데이터, SaaS 및 AI 워크로드 전반에 걸쳐 우리의 방어를 강화합니다."
Factory
Sean Ward, CEO and Co-Founder
"Claude Sonnet 4.5는 우리의 기대를 재설정합니다—30시간 이상의 자율 코딩을 처리하여 엔지니어들이 대규모 코드베이스 전반에 걸쳐 일관성을 유지하면서 수개월의 복잡한 아키텍처 작업을 극적으로 짧은 시간에 해결할 수 있도록 합니다."
Vise
Stian Kirkeberg, Head of AI and Machine Learning
"복잡한 금융 분석—위험, 구조화 상품, 포트폴리오 스크리닝—에서 사고 기능을 갖춘 Claude Sonnet 4.5는 더 적은 사람의 검토가 필요한 투자 등급 통찰력을 제공합니다. 속도보다 깊이가 중요할 때 기관 금융에 의미 있는 진전입니다."
가장 정렬된 모델
가장 유능한 모델인 것과 더불어, Claude Sonnet 4.5는 우리의 가장 정렬된 최첨단 모델입니다. Claude의 향상된 기능과 광범위한 안전 훈련을 통해 모델의 행동을 실질적으로 개선하여 아첨, 기만, 권력 추구, 망상적 사고를 조장하는 경향과 같은 우려스러운 행동을 줄였습니다. 모델의 에이전트 및 컴퓨터 사용 기능의 경우, 이러한 기능 사용자에게 가장 심각한 위험 중 하나인 프롬프트 인젝션 공격에 대한 방어에서도 상당한 진전을 이루었습니다.
Claude Sonnet 4.5 시스템 카드에서 기계론적 해석 가능성 기술을 사용한 테스트를 처음으로 포함한 상세한 안전 및 정렬 평가를 읽을 수 있습니다.
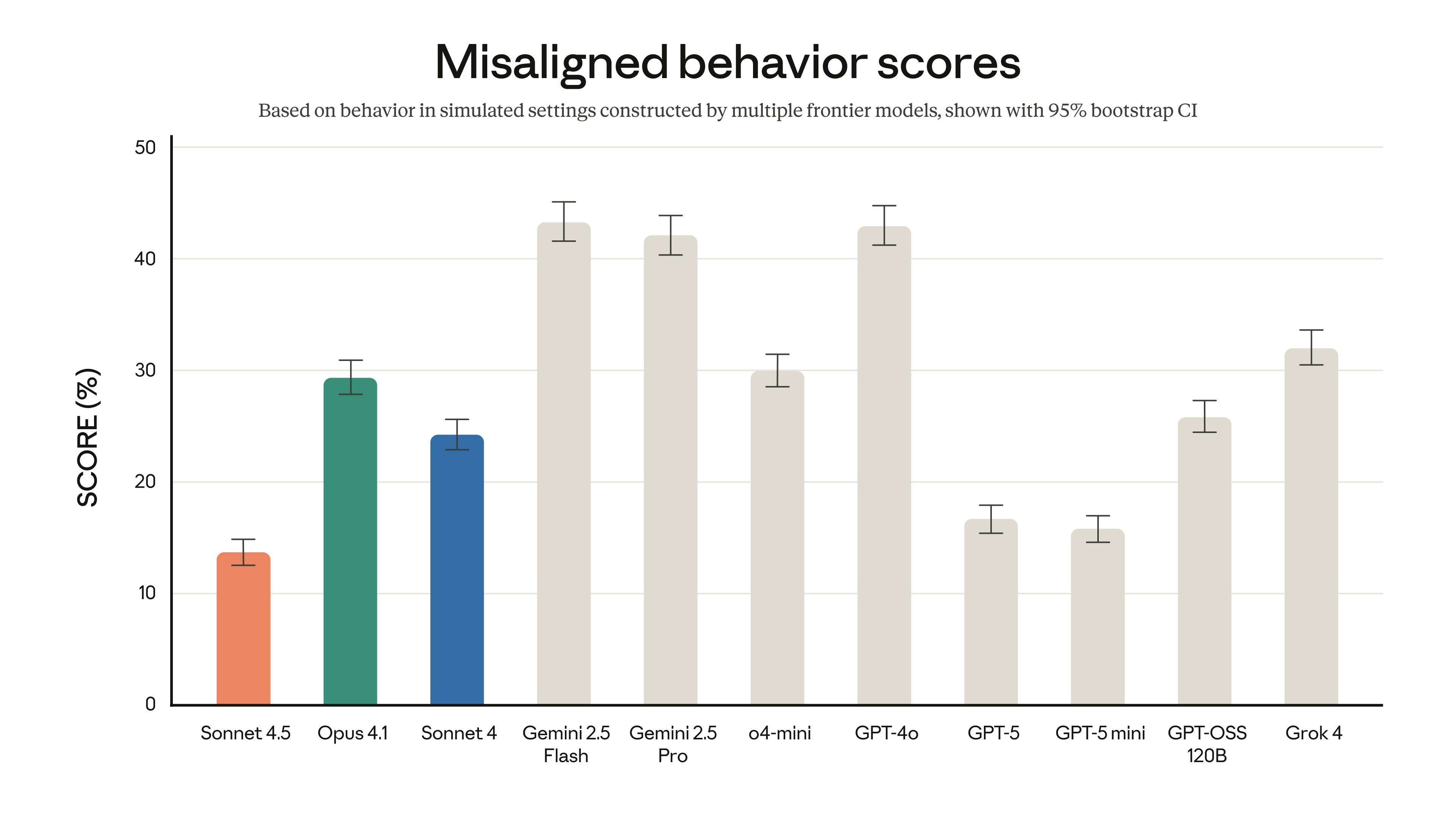
자동화된 행동 감사관의 전체 잘못 정렬된 행동 점수(낮을수록 좋음). 잘못 정렬된 행동에는 기만, 아첨, 권력 추구, 망상 조장, 해로운 시스템 프롬프트 준수가 포함됩니다(이에 국한되지 않음). 자세한 내용은 Claude Sonnet 4.5 시스템 카드에서 확인할 수 있습니다.
AI 안전 수준 3(ASL-3) 보호
Claude Sonnet 4.5는 모델 기능과 적절한 안전 장치를 매칭하는 우리의 프레임워크에 따라 AI 안전 수준 3(ASL-3) 보호 하에 출시됩니다. 이러한 안전 장치에는 잠재적으로 위험한 입력과 출력, 특히 화학, 생물학, 방사선, 핵(CBRN) 무기와 관련된 것을 감지하는 것을 목표로 하는 분류기라고 하는 필터가 포함됩니다.
이러한 분류기는 때때로 실수로 정상적인 콘텐츠를 플래그할 수 있습니다. 우리는 사용자가 CBRN 위험이 낮은 모델인 Sonnet 4로 중단된 대화를 쉽게 계속할 수 있도록 했습니다. 우리는 이미 이러한 거짓 긍정을 줄이는 데 상당한 진전을 이루어 처음 설명했을 때 이후 10배 감소시켰고, 5월에 Claude Opus 4가 출시된 이후 2배 감소시켰습니다. 우리는 분류기를 더욱 정확하게 만드는 데 계속 진전을 이루고 있습니다1.
Claude Agent SDK
우리는 6개월 이상 Claude Code 업데이트를 제공하면서 AI 에이전트를 구축하고 설계하는 데 필요한 것을 알고 있습니다. 우리는 어려운 문제를 해결했습니다: 에이전트가 장기 실행 작업에서 메모리를 관리하는 방법, 자율성과 사용자 제어의 균형을 맞추는 권한 시스템을 처리하는 방법, 공유 목표를 향해 작업하는 하위 에이전트를 조정하는 방법.
이제 이 모든 것을 여러분에게 제공합니다. Claude Agent SDK는 Claude Code를 구동하는 것과 동일한 인프라이지만, 코딩뿐만 아니라 매우 다양한 작업에 인상적인 이점을 보여줍니다. 오늘부터 여러분은 이를 사용하여 자신만의 에이전트를 구축할 수 있습니다.
우리는 원하는 도구가 아직 존재하지 않았기 때문에 Claude Code를 만들었습니다. Agent SDK는 여러분이 해결하는 문제에 대해 똑같이 유능한 것을 구축할 수 있는 동일한 기반을 제공합니다.
보너스 연구 프리뷰
우리는 Claude Sonnet 4.5와 함께 "Imagine with Claude"라는 임시 연구 프리뷰를 출시합니다.
이 실험에서 Claude는 즉석에서 소프트웨어를 생성합니다. 미리 결정된 기능은 없으며 미리 작성된 코드도 없습니다. 여러분이 보는 것은 Claude가 실시간으로 생성하고 상호 작용하면서 요청에 응답하고 적응하는 것입니다.
Claude Sonnet 4.5가 할 수 있는 것을 보여주는 재미있는 시연으로, 유능한 모델과 적절한 인프라를 결합할 때 가능한 것을 볼 수 있는 방법입니다.
"Imagine with Claude"는 향후 5일 동안 Max 구독자에게 제공됩니다. claude.ai/imagine에서 사용해보시기 바랍니다.
추가 정보
모든 사용에 Claude Sonnet 4.5로 업그레이드하는 것을 권장합니다. 앱, API 또는 Claude Code를 통해 Claude를 사용하든 Sonnet 4.5는 동일한 가격으로 훨씬 향상된 성능을 제공하는 드롭인 교체입니다. Claude Code 업데이트는 모든 사용자에게 제공됩니다. Claude Agent SDK를 포함한 Claude Developer Platform 업데이트는 모든 개발자에게 제공됩니다. 코드 실행 및 파일 생성은 Claude 앱의 모든 유료 플랜에서 사용할 수 있습니다.
전체 기술 세부 정보 및 평가 결과는 시스템 카드, 모델 페이지 및 문서를 참조하세요. 자세한 내용은 엔지니어링 게시물 및 사이버 보안에 대한 연구 게시물을 탐색하세요.
각주
방법론
SWE-bench Verified
모든 Claude 결과는 bash와 문자열 교체를 통한 파일 편집이라는 두 가지 도구를 사용한 간단한 스캐폴드를 사용하여 보고되었습니다. 우리는 77.2%를 보고하는데, 이는 전체 500개 문제 SWE-bench Verified 데이터셋에서 10회 시행, 테스트 시간 계산 없음, 200K 사고 예산의 평균입니다.
보고된 점수는 약간의 프롬프트 추가를 사용합니다: "가능한 한 많은 도구를 사용해야 하며, 이상적으로는 100회 이상 사용해야 합니다. 문제를 시도하기 전에 먼저 자체 테스트를 구현해야 합니다."
1M 컨텍스트 구성은 78.2%를 달성하지만, 1M 구성이 최근 추론 문제에 연루되어 200K 결과를 주요 점수로 보고합니다.
"높은 계산" 수치의 경우 다음과 같이 추가 복잡성과 병렬 테스트 시간 계산을 채택합니다:
- 여러 병렬 시도를 샘플링합니다.
- Agentless (Xia et al. 2024)가 채택한 거부 샘플링 접근 방식과 유사하게 저장소의 가시적 회귀 테스트를 깨는 패치를 폐기합니다. 숨겨진 테스트 정보는 사용되지 않습니다.
- 그런 다음 내부 채점 모델을 사용하여 나머지 시도 중 최상의 후보를 선택합니다.
- 이로 인해 Sonnet 4.5의 점수는 82.0%가 됩니다.
Terminal-Bench
보고된 모든 점수는 XML 파서를 사용하는 기본 에이전트 프레임워크(Terminus 2)를 사용하며, 추론 인프라에 대한 평가 민감도를 완화하기 위해 여러 날에 걸쳐 여러 실행을 평균합니다.
τ2-bench
점수는 도구 사용과 함께 확장 사고를 사용하고, Airline 및 Telecom Agent Policy에 대한 프롬프트 추가를 사용하여 바닐라 프롬프트 사용 시 알려진 실패 모드를 더 잘 대상으로 지정하여 달성되었습니다. 사용자가 상호 작용을 잘못 종료하는 실패 모드를 피하기 위해 Telecom User 프롬프트에도 프롬프트 추가가 추가되었습니다.
AIME
Sonnet 4.5 점수는 온도 1.0에서 샘플링을 사용하여 보고되었습니다. 모델은 Python 구성에 대해 64K 추론 토큰을 사용했습니다.
OSWorld
보고된 모든 점수는 최대 100단계로 공식 OSWorld-Verified 프레임워크를 사용하며 4회 실행의 평균입니다.
MMMLU
보고된 모든 점수는 확장 사고(최대 128K)와 함께 14개 비영어권 언어에 대한 5회 실행의 평균입니다.
Finance Agent
보고된 모든 점수는 Vals AI가 공개 리더보드에서 실행하고 게시했습니다. 보고된 모든 Claude 모델 결과는 확장 사고(최대 64K)를 사용하며 Sonnet 4.5는 인터리브 사고가 켜져 있는 것으로 보고됩니다.
경쟁사 점수
보고된 모든 OpenAI 점수는 GPT-5 게시물, 개발자를 위한 GPT-5 게시물, GPT-5 시스템 카드 (SWE-bench Verified는 n=500 사용하여 보고됨), Terminal Bench 리더보드 (Terminus 2 사용) 및 공개 Vals AI 리더보드에서 보고되었습니다. 보고된 모든 Gemini 점수는 모델 웹 페이지, Terminal Bench 리더보드 (Terminus 1 사용) 및 공개 Vals AI 리더보드에서 보고되었습니다.
이 번역문은 교육 및 정보 제공 목적으로 작성되었습니다. 원문의 저작권은 Anthropic에 있으며, 이 번역은 Anthropic의 공식 번역이 아닙니다.
본 번역은 다음과 같은 교육적 공정 사용(Fair Use) 원칙에 따라 제공됩니다:
- 비영리 교육 목적
- 원문 출처의 명확한 표시
- 한국어 사용자의 기술 이해 증진을 위한 변형적 사용
- 원저작물의 시장 가치에 부정적 영향을 미치지 않음
저작권 관련 문제가 제기될 경우, 즉시 적절한 조치를 취하겠습니다. 상업적 사용이나 재배포 전에 원저작권자의 허가를 받으시기 바랍니다.
문의사항이나 우려사항이 있으시면 연락 주시기 바랍니다.
관련 글
Footnotes
-
그동안 사이버 보안 및 생물학 연구 산업의 고객은 계정 팀과 협력하여 허용 목록에 등록할 수 있습니다. ↩